ゲノム(その生物の構成に必要な遺伝情報の一式)情報の登場によって、生化学、分子生物学および創薬そして疾病予防の研究は大きく変わろうとしています。ゲノム情報を有効に使うことによって、効率のよい実験系が構築できます。これまでは、部分的にしか把握できなかった遺伝子の全体像もわかりかけています。また、生物種間の比較ゲノム解析をすれば、設計図から見て、「ヒトがヒトであるとはどういうことか」といった種の特徴付けが可能となりますし、一方で、共通性を軸に「生命とはなにか」といったより踏み込んだ解析への道が開けようとしています。しかし、ゲノム単位の情報は、その膨大さから計算機なくしては解析に着手することができません。こうして、生物情報の処理や解析に特化したコンピュータ技術あるいは解析理論を研究する分野が誕生しました。それが、バイオインフォマティクスです。すでに160種を超える微生物で完全長ゲノム配列が決定されていることからも推測できるように、今やバイオインフォマティクスは、特別なものではく、生命現象の解明には必要不可欠の道具なりつつあります。しかし、この分野が芽生えたのは、ほんの10年前であり、バイオインフォマティクスを使いこなせる人材は、日本はもとより世界中で不足しています。当研究室では、バイオインフォマティクスを使いこなせる人材を育成するとともに、バイオインフォマティクスを軸にしたゲノム・遺伝子解析をとおして、創薬に貢献できるもっと新しい分野「ファーマコインフォマティクス」の創造を目指しています。
バイオインフォマティクスをするには、何を勉強したらよいでしょうか?といった質問を受けることがあります。私は、生物系のデータ処理を効率よく扱うためのいわば演習テーマと、目的に応じたアプリケーションを開発していくための知見を深める理論テーマに大別されると思います。いろいろな切り口がありますが、各項目を以下の表にまとめてみました。
演習テーマを身につけられれば、配列情報を中心とした生物情報処理に対しては大抵対応できるようになるでしょう。一方、理論テーマは、すべてが必要となるわけではなく、目的に応じて取捨選択できるものです。3年次の選択科目として開講している「バイオインフォマティクス1、2」では、主に演習テーマについての解説を展開しています。まずは、触れてみることが大切だと思いますので。卒研次あるいは大学院で理論テーマのいくつかを習得し、独自の解析を展開することを目指せばよいと思います。
バイオインフォマティクスを基盤に、生命現象(遺伝子機能、制御など)の解析を目指します。
「ドライバイオロジー」≠「データ処理・データベース」ではありません。
< ドライ >
● 大規模データを加工し、目的に応じたデータベース化
● パラメータを変えて実験
● 解析用データの取得
● データ解析
< ウェット >
● 実験系のデザイン
● 試薬や材料の調合を変えて実験
● データの取得
● データ解析
ゲノム構造や遺伝子配列の解析など、一次配列データからの知識抽出を基盤としています。
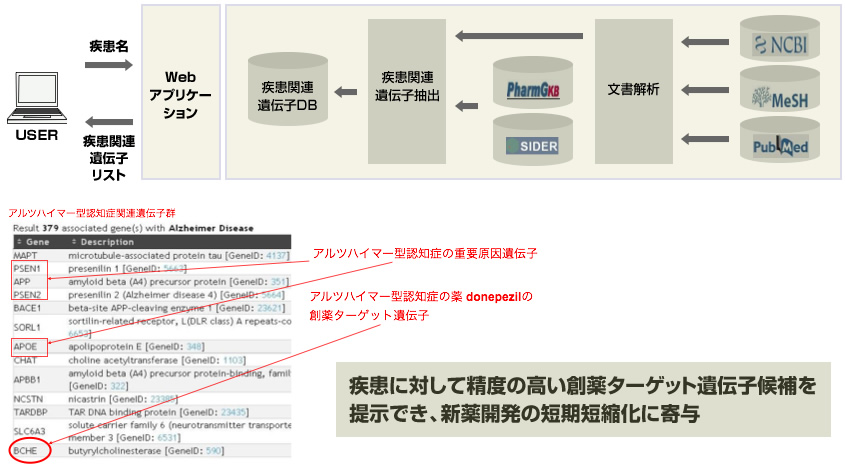
一次配列から、遺伝子機能をどこまで推測できるのか?
薬のターゲットとなり得る遺伝子はどのように特徴付けられるのか?
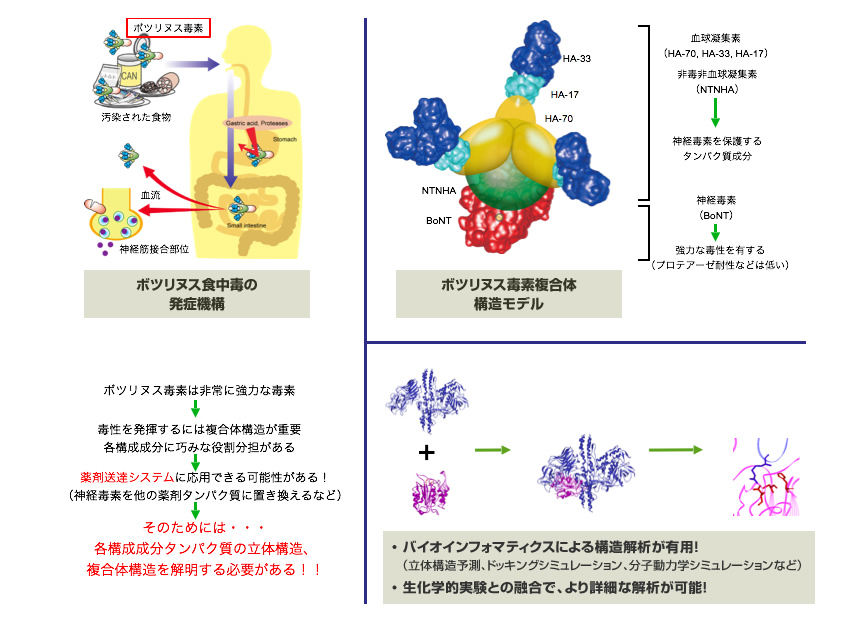
タンパク質の立体構造予測、タンパク-タンパクまたはタンパク-DNAのドッキングシミュレーション、薬物動態のシミュレーションを基にした分子機能の解明を目指します。
=> 生化学的実験が追いつけない研究をし、補完する。